



基于标签的电影推荐算法研究

张萌, 纪佳琪
(河北民族师范学院, 数学与计算机科学学院, 河北, 承德 067000)
随着互联网时代的到来,日益增长的数据信息使得人们在电影网站获取电影资源的效率变低,这就要求我们的网站尽可能根据用户留下的信息去分析用户可能感兴趣的电影资源并推荐给用户[1]。传统的推荐算法有很多种,基于物品的推荐算法,基于用户的推荐算法等,而近年来基于标签的推荐算法逐渐应用于多个领域[2-3]。将基于标签的算法应用于现实电影推荐系统中可以为用户带来很大的便利,也可间接地促进电影产业的发展[4]。
推荐算法的目的是联系用户和物品,标签推荐算法中的标签是联系用户和物品的媒介。标签推荐算法的原理是进行用户兴趣建模,需要根据训练数据构建矩阵得出用户对所有物品的喜好程度矩阵,在得到的计算结果中选取前K个推荐给用户。
2.1 计算用户对标签的喜好程度
用户对一个标签的认可度可以使用二元关系来表示,这种关系只有“是”“否”两种结果,实际上难以准确地表达出用户对物品的喜好程度。因此,我们可以用连续数值来表示用户对物品的喜好程度,范围在0~1之间,便于对喜好程度进行区分和排序。
用户对标签的喜好程度计算式为
(1)
式中,分子为用户对物品的评分score与物品与标签的相关度rel乘积之和,分母为物品与标签相关度的和,u代表用户,m代表电影,t代表标签。
下面对具体计算过程进行说明。
例如:有1位用户、3部电影和3个标签。由图1可得,用户u对电影1、电影2和电影3的评分分别为4分、6分和8分(例子中最高设定为10分)。
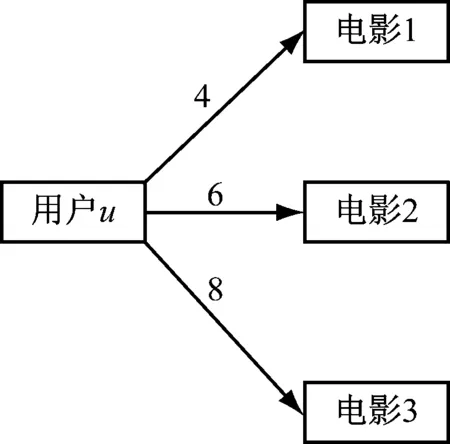
图1 用户u对电影的评分score(u,m)
由图2可以看出,电影1与标签a的相关度为0.5,与标签b的相关度为0.7,与标签c的相关度为0.4。由图3可以看出,电影2与标签a的相关度为0.3,与标签b的相关度为0.6,与标签c的相关度为0.8。

图2 电影1与标签的相关度rel(1,t)
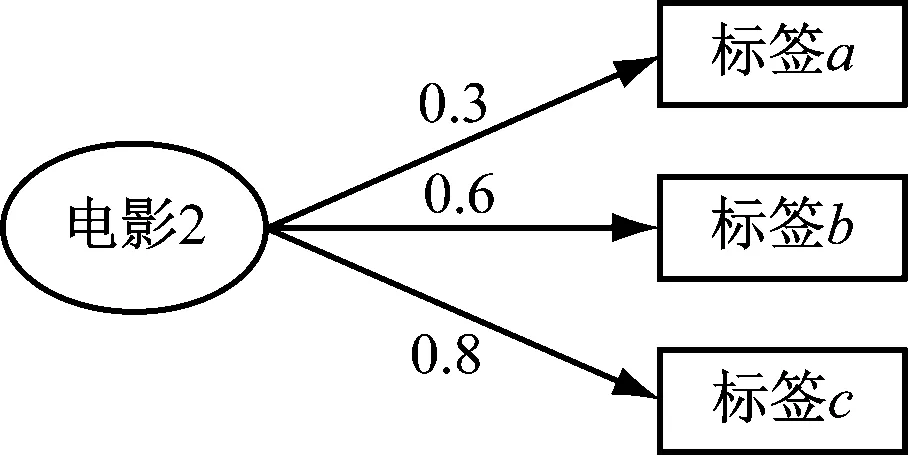
图3 电影2与标签的相关度rel(2,t)
由图4可以看出,电影3与标签a的相关度为0.4,与标签b的相关度为0.7,与标签c的相关度为0.6。
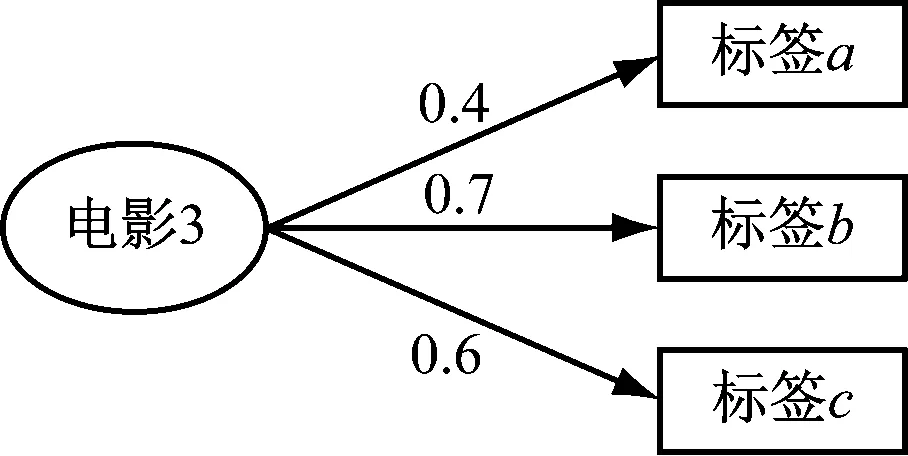
图4 电影3与标签的相关度rel(3,t)
根据式(1)得到用户u对标签a的喜好程度ratio(u,a)为
(4×0.5+6×0.3+8×0.4)/(0.5+0.3+0.4)=5.83
用户u对标签b的喜好程度ratio(u,b)为
(4×0.7+6×0.6+8×0.7)/(0.7+0.6+0.7)=6
用户u对标签c的喜好程度ratio(u,c)为
(4×0.4+6×0.8+8×0.6)/(0.4+0.8+0.6)=6.22
2.2 优化用户对标签的喜好程度
式(1)适用于用户评分行为较多的情况,假设一个用户对标签的评分行为较少,那么用上面的公式就会导致推荐结果产生相对比较大的误差。
比如当用户u只对电影1给出了评分时,根据式(1)可计算得到:
用户u对标签a的喜好程度为4×0.5/0.5=4
用户u对标签b的喜好程度为4×0.7/0.7=4
用户u对标签c的喜好程度为4×0.4/0.4=4
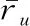
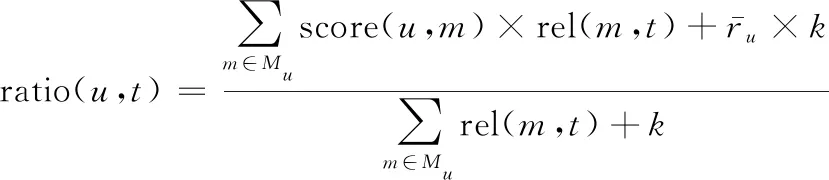
(2)
根据式(2)重新计算用户对标签的喜好程度ratio(u,t),式(2)中加入的平滑因子k是一个不确定的值,在本节中将平滑因子k取1。由此可以得出:
用户u对标签a的喜好程度ratio(u,a)为
(4×0.5+6×0.3+8×0.4+6×1)/(0.5+0.3+0.4+1)=5.91
用户u对标签b的喜好程度ratio(u,b)为
(4×0.7+6×0.6+8×0.7+6×1)/(0.7+0.6+0.7+1)=6
用户u对标签c的喜好程度ratio(u,c)为
(4×0.4+6×0.8+8×0.6+6×1)/(0.4+0.8+0.6+1)=6.14
假设用户u只对电影1给出了评分时,根据式(2)可计算出用户u对标签a、b、c的喜好程度分别为5.18、5.33、5.43。优化后即使用户对物品评分行为较少的情况下误差也缩小了很多。在评分信息正常的情况下,式(2)计算得到的用户对标签的喜好程度顺序没有发生变化。
2.3 计算用户对标签的依赖程度
2.1和2.2计算的是用户对标签的喜好程度,是从用户的角度进行分析。一个标签如果被用户标记的次数越多,则说明该用户对标签的依赖程度越大。因此本小节使用TF-IDF算法来计算每个标签的权重,用这个权重来表达用户对标签的依赖程度。TF-IDF算法的中心思想是:如果某一个词语在一篇文章中出现的频率TF比较高,同时在其他文章中出现的频率比较低,那么这个词语就很可能反映了这篇文章的特性,TF为词语出现的频率,IDF为逆文档频率[5]。TF-IDF所表达的实际上是TF与IDF的乘积。
计算用户u对标签t的依赖程度,首先计算TF值即用户u使用标签t标记的频率:
(3)
式中,分子部分表示用户u使用标签t标记的次数,分母部分表示用户u使用所有标签标记的次数之和。
计算IDF值:
(4)
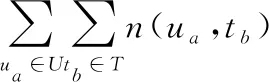
最终,用户对标签的依赖程度计算公式为
TF-IDF(u,t)=TF(u,t)×IDF(u,t)
(5)
用户u对标签的兴趣度Tu的计算公式为
Tu=ratio(u,t)×TF-IDF(u,t)
(6)
2.4 构建物品标签基因矩阵
在标签系统中,每个物品都可以被看作与其相关的标签的集合。标签基因可用来表示标签与物品之间的关系,采用标签基因可以为每个物品计算出一个标签向量[6]。
例如2.1中电影1的标签基因为电影1分别与标签a、标签b和标签c的相关度组成的矩阵,即Ti=[0.5,0.3,0.4]。电影1、电影2和电影3的标签基因矩阵如表1所示。

表1 电影的标签基因矩阵Ti
根据训练数据可以构建所有物品的标签基因矩阵Ti和用户对标签的兴趣度矩阵Tu。Tu的计算方式在2.3已经给出说明,按照上述计算方式构建矩阵Tu。
计算标签基因矩阵Ti需首先计算用户与标签的相关度。例如有3部电影A、B、C,3个标签a、b、c。有如下几条数据:用户1为电影A评分,对应标签为a;
用户2为电影A评分,对应标签为a;
用户2为电影B评分,对应标签为a;
用户3为电影A评分,对应标签为b;
用户3为电影A评分,对应标签为c。根据以上数据构建,见表2电影、标签、用户关系对应表。进而可以构建,见表3电影与标签对应关系矩阵,矩阵中的数字表示对某部电影评分同时赋予对应标签的用户数量(如表3矩阵中数字2表示对电影A评分,对应标签为a的用户数量为2)。
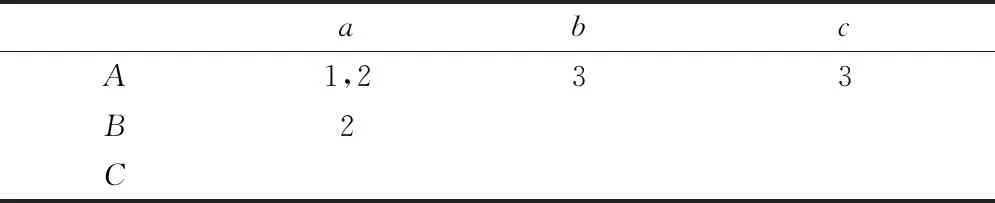
表2 电影、标签、用户关系对应表

表3 电影与标签对应关系矩阵
计算电影A与标签a的相关度为2/(2+1+1)=0.5。同理,可以计算出所有电影与标签对应的相关度。
根据物品与标签的相关度数据构建物品的标签基因矩阵Ti,由于电影与标签数据过多,本文在计算电影与标签的相关度时,只要电影有对应的标签就将相关度标记为1,否则标记为0。
综上,则用户对物品的喜好程度矩阵T(u,i)计算公式为
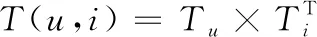
(7)
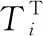
3.1 评价指标
第2部分介绍标签推荐算法的数学建模过程,本部分将标签推荐算法应用于具体数据集中,为不同用户推荐喜好程度较高的电影,同时得到推荐算法的准确度。本实验将推荐准确度作为算法评价指标。
推荐准确度的计算公式为
(8)
式中,|R(u)|表示推荐电影的个数,|T(u)|表示在训练的数据集中用户有过评分行为的电影个数,|R(u)∩T(u)|表示推荐的电影与所有评过分的电影相交的个数。
3.2 数据集
本实验中使用的数据集是MovieLens中的ml-latest-small数据集,主要用到ratings.csv、tags.csv和tags1.csv三个数据。其中,包含了610位用户对9 742部电影的100 836条评分记录,用到3 683条标签数据。ratings.csv数据用到3列:用户编号userID、电影编号movieID和用户对电影的评分weight。tags.csv数据用到3列:用户编号userID、艺术家编号artistID以及标签编号tagID。
由于实验中使用的是数值型的标签ID,因此对tags.csv中的tagID一列做数据处理。将字符串型tagID数据转换为数值型数据,同时要将artistID一列重命名为movieID,最终得到数据tags1.csv。表4展示了3个数据中每列数据分别包含的数量。
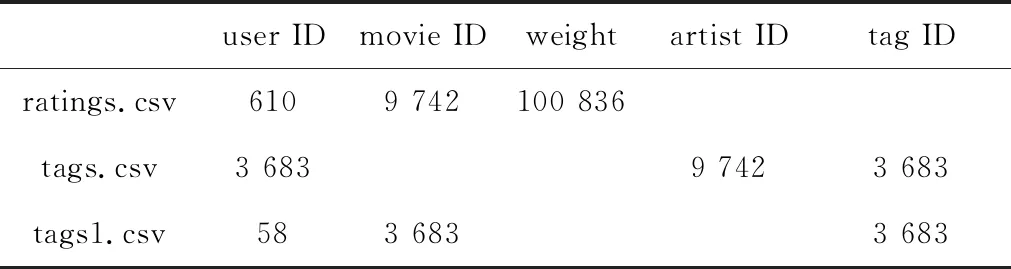
表4 用户评分标签数据对应数量
3.3 实验
本节选取实验结果中289号用户的推荐结果进行说明,其他用户推荐结果原理相同。
表5为289号用户推荐电影的结果。从表5可以看出,本次共为289号用户推荐了5部电影,推荐结果为第一部是ID为3的电影,289号用户对电影3的喜好程度为9.398 259 021 019 065。第二部是ID为1101的电影,289号用户对电影1101的喜好程度为3.066 156 427 847 680 7。第三部是ID为34405的电影,289号用户对电影34405的喜好程度为3.066 156 427 847 680 7。第四部是ID为82459的电影,289号用户对电影82459的喜好程度为 3.066 156 427 847 680 7。第五部是ID为96861的电影,289号用户对电影96861的喜好程度为3.066 156 427 847 680 7。通过数据观察到用户对电影的喜好程度是由高到低排序的,根据喜好程度优先为用户推荐相应的电影。
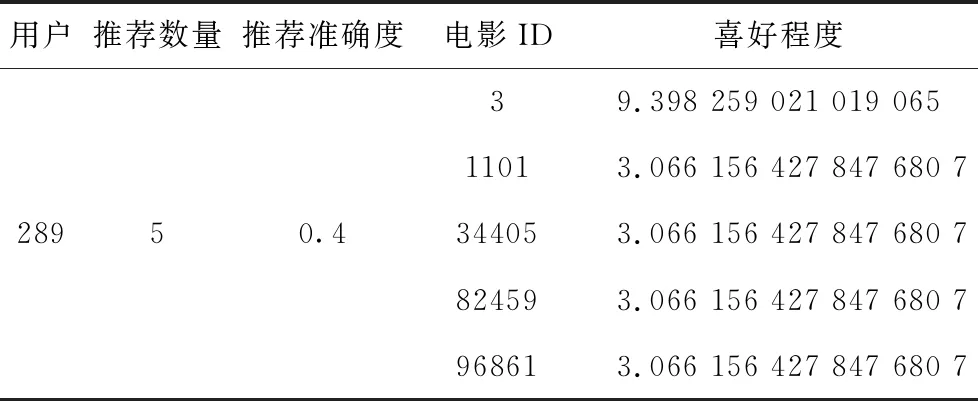
表5 289号用户推荐结果
本次推荐的准确度为0.4,代表本次为289号用户推荐的5部电影中有2部电影是用户有过评分行为的。
3.4 结果分析
3.3的结果展示是为任意一位用户推荐电影的准确度,整个实验的数据是对多位用户进行多次推荐。因此本节对不同K值下所有用户的推荐准确度取平均值进行分析,K值取5到20。(保留三位小数)
如图5所示,K值取5时得到的推荐准确度平均值为0.586,K值取20时得到的推荐准确度平均值为0.372。K的取值在5到20区间时,推荐数量K值越大,推荐准确度越低。
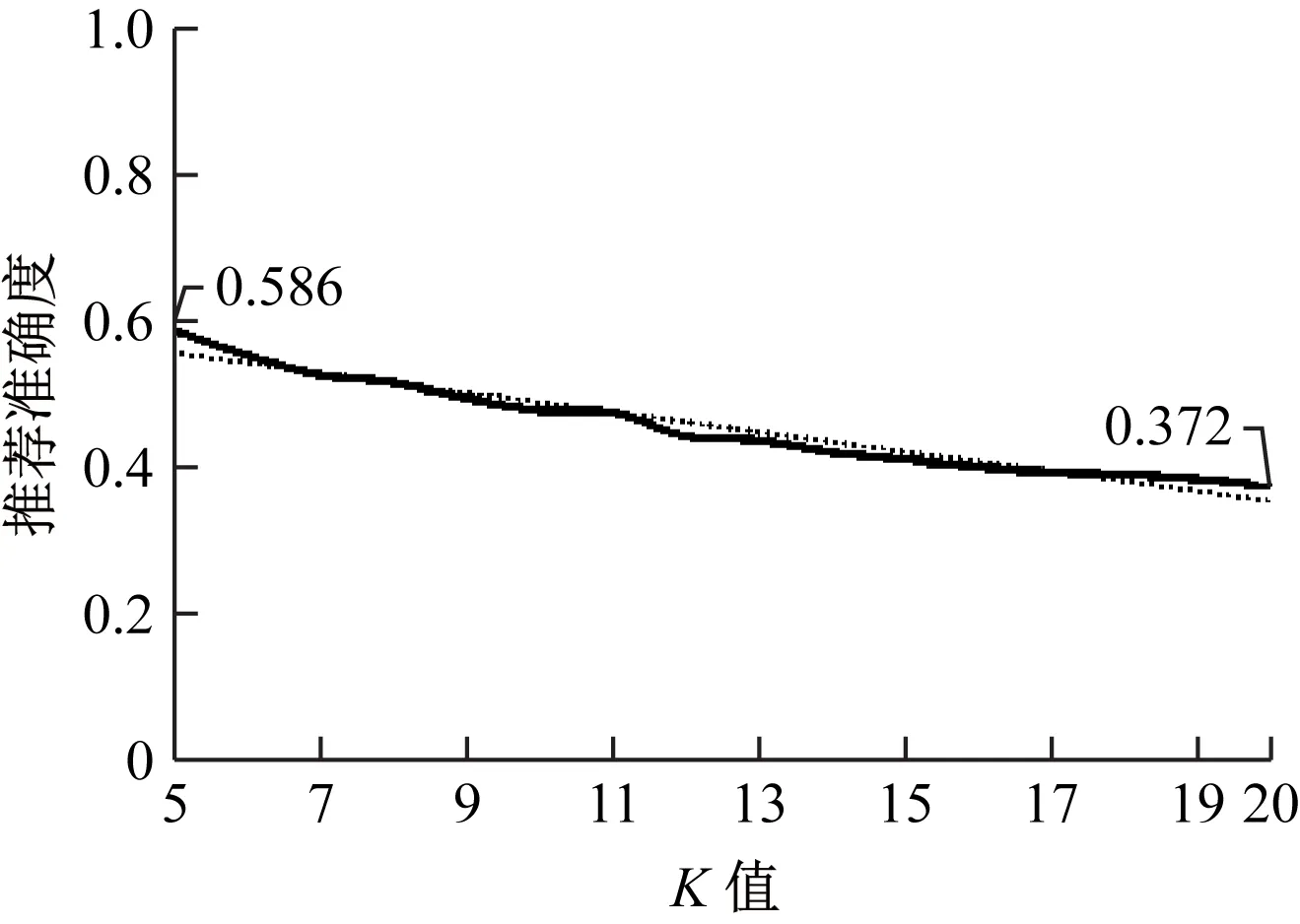
图5 K值与推荐准确度关系图
计算得到K的多个取值下推荐准确度的值,最终将所有推荐准确度的值求取平均值得到标签推荐算法的推荐准确度为0.453。
本文首先对基于标签的推荐算法进行了介绍,并阐述了标签推荐算法的计算过程,重点是根据用户与标签的关系计算出用户对电影的喜好程度,最终按照喜好程度的高低将前K部电影推荐给用户。将标签推荐算法应用于电影推荐系统可以优化电影网站的推荐准确度,为用户带来便利,提高用户对电影网站的好感度。
猜你喜欢准确度物品标签称物品小学生学习指导(低年级)(2022年5期)2022-05-31“双十一”,你抢到了想要的物品吗?疯狂英语・初中天地(2021年11期)2021-02-16谁动了凡・高的物品少年漫画(艺术创想)(2019年2期)2019-06-06幕墙用挂件安装准确度控制技术建筑科技(2018年6期)2018-08-30无惧标签 Alfa Romeo Giulia 200HP车迷(2018年11期)2018-08-30不害怕撕掉标签的人,都活出了真正的漂亮海峡姐妹(2018年3期)2018-05-09动态汽车衡准确度等级的现实意义中国交通信息化(2016年5期)2016-06-06标签化伤害了谁公民与法治(2016年10期)2016-05-17一款基于18位ADC的高准确度三相标准表的设计电测与仪表(2016年18期)2016-04-11科学家的标签少儿科学周刊・少年版(2015年2期)2015-07-07