



����GRU������Ŀ��ƶ�����Ȥ����Ƽ�ϵͳ

ʷ�䣬�� ��
(���Ƽ���ѧ�˹�����ѧԺ����� 300457)
�����������Ÿ����ֳ��ն��豸�Ŀ��ٷ�չ�Լ�ȫ��λϵͳ(global positioning system��GPS)��λ�������ս����죬�о���Ա����ҵ����������ô����ĸ��˵���λ����Ϣ[1].��������������Ҳ�������û���Ȩ��ǰ���»�÷ḻ��λ�ú켣��Ϣ������Ϊ�û��ṩ����λ�õķ���[2]�����綨λ���������ƶ��е������ȹ��ܷ���.�������ʱ�չ켣����Ϊ�û��ṩ��ݵ��Ƽ��������������Ϊ������Ա��ע���ص�[3].�Ը��˻�ռ�ļ�������������ھ��������ƶ�ģʽ�����е��ȵ�������Ȥ��ֲ�����Ϣ[4]��Ϊ���������ṩ����������֧�ź�Ч�ķ���.���Ƽ�ϵͳ�о������У�������Ȥ����Ƽ���Ӧ�ý�Ϊ�㷺���Ƽ�����.
Ŀǰ������Ȥ����Ƽ��㷨�ܴ�̶����������������㣺���еĹ켣�����Ƶ�ʱ���˶��켣[5]�����Լ��Ը����Ⱥ����Ϊ�ķ������.���͵�Ӧ�ó��������˼������켣���罻��վǩ����.����Ӧ�ó��������������������������Ϊ������ͨ�����û���Ϊ���з����õ��������Ⱥ���ƶ�ģʽ�����е��ȵ�������Ȥ��ֲ�����Ϣ�������ﵽ�ó���������ӱ�ݡ����ٵ�·ӵ�µ�Ŀ�ģ����ղ����˻�����Ȥ����Ƽ�ϵͳ.�����о��Ķ����������Ǿ�̬��Ȥ�㣫��̬�û��������о��Ĺ�ע������ڶԶ�̬�û��켣�ķ���Ԥ�������ϣ���ȱ�ٶ���Ȥ��λ�ñ仯�Ĺ�ע.
Ȼ������ʵ����������Ƕ�̬�仯�ģ���Ȥ�㲢�Ƕ��Ǿ�̬��.������Կ��ƶ�����Ȥ��������о�.һ�����͵ij�����������˼Ӣ��Ƽ�����˾(PerceptIn��˾)���й����ڹ�ҵ����������������ۻ���.���û��ĽǶȿ������������ۻ����ǿ��ƶ�����Ȥ�㣻
�����������ۻ����ĽǶȿ����û�������˵Ҳ�ǿ��ƶ�����Ȥ��.������ҵ��ʽ���Ƽ�������Ҫ�����ƶ������أ����봫ͳ��̬��ʽ���Ƽ��������ű����ϵ�����.��ˣ����Ƽ�ϵͳ�о��У�����̬��Ȥ����չ�����ƶ���Ȥ����龰�ϲ�ʵ����Ӧ���Ƽ��㷨����һ���о����µ㣬Ҳ��һ���о��ѵ�.������չ����ʵ�����о��й㷺��Ӧ�û����Լ���Ӧ���Ƽ�����[6].
������Ҫ��������⡢ʵ�ַ����Լ����µ����£�
(1)ͨ��������Ȥ��ʱ�չ켣��������Ȥ��Ŀ��ƶ��ԣ��������̬�������Ƽ��㷨����������.
(2)���û���ʱ�չ켣��Ϣ������ȡ��Ȼ�����������㼶��Ǩ��ѧϰ�������������Ԥ�������ͷ������������öԱ�ѧϰ��չѵ�����ݵ�������ģ.Ϊ��ʹ��չ�����ݼ��ĸ��ʷֲ����䣬����ʹ��������ֵ�����������(maximum mean discrepancy��MMD)�Լ� TrAdaBoost���������(expectation maximization��EM)�㷨��������������ˣ�ȥ��������Ҫ�������.
(3)ʹ���ſ�ѭ��(gate recurrent unit��GRU)��������û���δ��ʱ�չ켣����Ԥ�⣬�����û��ľۼ���������ص�����������Ȥ��λ��.
(4)���ս��Ԥ���ʱ�ս����Ϊ�û����к����Ƽ���ʹ���ƶ���Ȥ�����û��ܹ���һ����ʱ�շ�Χ�ڽ��н���.
ʱ�չ켣Ԥ��[7]�Ļ���ʵ�ֹ����Ƕ�ʱ���������ݽ��з�����������ɽ�ģ���ڴ˻����Ͻ���Ԥ��[8].���Խ�ʱ������Ԥ�⿴���Ƕ�ʱ�����еķ����ڿռ��е���չ�����е�ʱ�չ�ϵ����Ϊ��ģ�����IJ�ͬ����������.Cliff��[9]�� 1975�����ʱ��������ƶ�ƽ��ģ�� STARMA�����״������ʱ�����н�ģ�Ŀ��.Martin��[10]������ʱ��������ƶ�ģ�ͣ���ģ���ܹ�����ʱ���ӳ����ӽ�ʱ���ӳٺͿռ��ӳ������������Ӷ������ؽ���ʱ��һ�廯ģ��.���ڷ�ƽ�ȡ�������ģ�ͣ������ʱ�����л��ģ�ͣ�����α�Ҷ˹ģ�͡�״̬�ռ�ģ�ͺͿ������˲��ȷ����ں�����.��������������[11-12]��֧��������[13]�ȷ���Ҳ����չ��Ӧ�õ�ʱ�����н�ģ��Ԥ����о��У�����ʱ������������ STANN[14]��ʱ������֧��������STSVR��.��������[15]�����������ֵ�ֽ�ģ�ͺ��Իع���ֻ���ƽ��ģ�͵�ʱ�����зֽ��Ԥ�⣬���о������������Ƚ�����ѵ��ʱ��ɱ����������Ԥ�⾫��.
Ҫ�����ij�������ʱ���˶�Ԥ�����Ƽ��������û������⣬����Ҫʹ���ʺϵ�ʱ����Ϣ�Ƽ��㷨.Ŀǰ�й�ʱ�չ켣����Ȥ���Ƽ����ͷ�Ϊ���ࣺһ�ǵص��Ƽ�������Ϊ�û��Ƽ��̵ꡢ�ݵȣ�
�����г��Ƽ�������Ϊ�û��Ƽ�����·�ߡ�Ϊ�û�������С���۵�·��.
������Ȥ����Ƽ�ϵͳ��Ӱ�����ش��¿ɹ���Ϊ 4��[16]������������Ӱ�졢ǩ������Ӱ�졢�罻����Ӱ��͵ص�������ϢӰ��.��������Ӱ���Ǹ��ݿռ�켣���ݽ����Ƽ�����Tobler��[17]��1970�������һ����ѧ���÷���ǿ�������ռ�ľ����Ǿ����������ƶȵĹؼ�������Խ�������ƶ�Խ��.ǩ������Ӱ���ǻ���ʱ�����ݽ����Ƽ����� Saleem��[18]�����������λ�ù켣ģ��Ϊ������ͬ������.�÷�����Ȼ�����γɽϺõ��Ƽ�����������������������.Ҳ���о���Ա�����һ���ʱ����еȷ֣���ʱ��ֶη����һ����ѧ��������ںϣ�����ʱ����Ȥ���Ƽ��㷨[19].�罻����Ӱ���Ǹ����罻������Ϣ�����Ƽ����� Gao��[20]����켣���ƶ�Խ����˴��Ǻ��ѹ�ϵ�Ŀ�����Խ���������Ը��ݵ���λ�ú��罻��ϵΪ�û��Ƽ���Ȥ��.�ص�������ϢӰ���Ǹ����û��Ա��Ƽ��ص���������ݽ����Ƽ��������о���ҪӦ����ӰԺ���֡������ֵȷ���.Zhao��[21]����������Ϣ��Ϊ���ʵص�Ĵ��������ڽ�����Ȥ��������Զ���������Ƽ����.Yin��[22-23]����˻��ڱ�Ҷ˹����ģ�͵��Ƽ�������������û����µص�ĸ���Ȥ�̶ȣ���ϳ����ȵ���û��켣ͣ����������Ȥ���Ƽ��б�.
���������е��о������ϣ������һ�ָ���������ṹ������ʵ�ֿ��ƶ�����Ȥ����Ƽ������ҽ�һ������Ƽ������ȷ��.
�����㷨��Ҫ����3������ģ�飺ģʽGRU����ģ�顢��GRU����ģ���Լ���������ģ��.
(1)ģʽ GRU ����ģ�飺ͨ���ں�Ǩ��ѧϰ�������ģʽѧϰ����Ŀ����ѧϰ�������ݼ��еĶ�̬ʱ���˶�ģʽ������ѵ�����ܹ���ģʽ����Ԥ�������.��ѧϰ���������ù�һ���ķ��������ݽ���Ԥ����������ͬ��Χ���������ϵ�ͬһ��Χ��.
(2)�� GRU����ģ�飺ͨ���ں϶Ա�ѧϰ������ɵ�ѧϰ����Ŀ������չĿ��ѵ��������������.�ڱ�֤��չ���������ʷֲ����������£��������ķ���������ѵ�����ܹ����ݵ�ǰʱ�յ�Ԥ����һλ�õ�����.
(3)��������ģ�飺�ڹ���ʱ���л����ص����ã�������������������ʽѡ����ģʽ GRU�Ľ����Ϊ������ǵ�GRU�Ľ����Ϊ���.
ͼ1(a)Ϊ���ķ�������ļ�������.���������ɵ� GRU����ģ�顢ģʽ GRU����ģ�����������ģ�鹲ͬ���գ��� 3������ģ��Эͬ������������ս��.ͼ1(b)Ϊ���ķ�����������ݺ�������������.�������������ߣ����Ա�ѧϰ���ֺ�Ǩ��ѧϰ����.�Ա�ѧϰ���֣��������ݼ��ֳɲ��Լ���ѵ������Ȼ�����öԱ�ѧϰ���Խ�ѵ������������������չ�����ñ�������������������˷�����չ������ݼ����й��˴�������ȷ����չ������ݼ����������ʷֲ����䣬���մﵽѵ������Ч�ĵ� GRU�����Ŀ��.Ǩ��ѧϰ���֣��������ݼ����Ƶ��ⲿ���ݼ��ܹ��ṩ���õ�ʱ����Ϣ������Ǩ��ѧϰ����ѧ����ͬ���ݼ���ʱ���˶��ϳ��ֳ��Ĺ�ͬ���ɣ���Щ��ͬ����Ҳ�ɿ���������Ч��������Ԥ�����ܵ�ѵ������.�������ֵĽ�����ھ�������ģ��Ŀ����½���ѡ������������յõ��Ƽ����.����Ǩ��ѧϰ�ͶԱ�ѧϰ���Ե�Ŀ���Լ��������ڣ����������ݼ���ģ��С������£���Ȼ�ܹ�ѵ����Ԥ��ȷ�ȸߡ���������ǿ��ģ��.

ͼ1 ����ļ��������Լ����ݺ�������������Fig.1 Calculation process��data and sample processing flow of the network
2.1 GRU����
�ڱ��ķ����У�GRU ����[24]����ֱ���Ǩ��ѧϰ���ԺͶԱ�ѧϰ���Խ����ںϣ�ʹ֮����ɶԵ��Լ�ģʽ��Ԥ��.������ x�������ݼ���һ���û�����������ʱ��λ����Ϣ��x ={�� ,xt-1, xt, xt+1,��}.�����ڲ����ݵ����ʱ��˳����� x����Ϊ���������ں��洦����������Ҫ�� x�ڲ������ݵ�������������Ϊ�˷��㣬�����ʾ�ɼ��ϵ���ʽ������xtΪ�û��� tʱ�̲���������(�û���ǰ��ʱ��λ��)����Ϊ����GRU��������벿��.��ʾ���û���ǰ��ʱ��λ��״̬���õ���״̬.


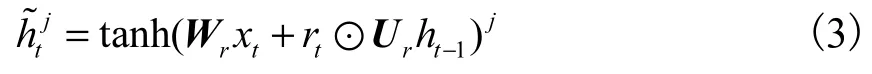
ʽ�У���Ϊ sigmoid������
Wz��WrΪȨ�ؾ����������Ա任��
Uz��Ur�ֱ�ΪȨ�ؾ���Wz��Wr�任��ı�����ʽ��
���������(Hadamard product)��
rtΪһ�����õ�Ԫ�����ر������� rtj�����õ�Ԫ��ʹ��Ԫ������ǰ�ļ���״̬.
������rtj������ŵļ������ƣ�Ϊ

���յõ��û���һʱ�̵�Ԥ���yt��Ϊ����GRUģ������

ʽ�Ш���ʾ���о���ӷ�����.
��Ҫע����ǣ�GRU���紦���������漰����ʱ�յ���ʱ�� t�ĸ��������������Ľ���±�Ҫע�� t�����ں���ľ�������ģ���в��漰ʱ��������±�ʡ����ʱ��t.
2.2 ����Ǩ��ѧϰ��ģʽGRUѵ��
����Ǩ��ѧϰ����[25]ѵ��ģʽ GRU.����Ǩ��ѧϰ��չ����ѵ��������ṹ�����ݼ������ķ�����Ҫ�����е��û�ʱ�չ켣���ݡ������ȸ߲�֪ʶ����ת�������ڽ���µĹ켣Ԥ������.��ʹ�Dz�ͬ��ʱ�չ켣���ݼ����������ռ�Ҳ����һ���Ĺ�ͬ�ԣ������Ϳ��Բ���������Ǩ�Ʒ��������������ͬ������.���ķ���Ӧ�õ������ݼ����ⲿ���ݼ������������ݼ���Ϊѵ�����Ͳ��Լ����ⲿ���ݼ����õ�����ͬ�����ʱ�յ����ݼ���.���ô��ⲿ���ݼ���ȡ����ʱ�չ켣��ѵ�����ݽ������ݣ���ʵ���˶�ģʽ���ָ�֪ʶ��Ǩ��ѧϰ.
��ͼ2��ʾ����ʱ��Ϳռ�����ݵ�Ƕ���������Ǩ��ѧϰ�����У�Ӧ���û����˶�ģʽ����Ǩ��ѧϰ�������Ƕ��û������ʱ�յ����Ǩ��.
ͼ2 ֱ������ת��ΪģʽGRU��ѵ�����ݸ�ʽFig.2 Convert rectangular coordinates to training data format of the mode GRU
Ʃ�磬A�û��ڼأ�B�û����ҵأ����ǵ��ס������ؿ��������Զ���� A��B�û����õĽ�ͨ���߲�ͬ������ A��B���ߵ�������ֱ�ӽ���ƥ��ѧϰ.���ǣ��ڼ���ʱ������A��B�û��Dz��л��Ǽ�ʻ������A��B���߶������������ϡ�裬�ڼ��ٹ���������������ܼ�������ת���Ҳ�����Ƶ��˶�ģʽ.��ˣ�Ӧ�öԲ�ͬ�û��ɼ�������ʹ���ܶȾ���(density-based spatial clustering of applications with noise��DBSCAN)��������Ԥ�Ⱦ��࣬�Խ���켣�г��ֵ���ʱ��פ��ij�أ������������ظ����������⣻
Ȼ�����ù�һ�������������û��������ݵĶ������죬�����ⲿ���ݼ������������ģʽ���й�GRUѧϰ���������ʱ�չ켣ģʽ��Ǩ�ƣ�����ģʽGRU�����Ԥ��������ӳ�䵽ʵ�ʿռ��У��ﵽ����ģʽ GRU�ṩ�ɽ���Ķ�̬�켣ģʽ��Ŀ��.�����ݲ㼶��ʵ�ֶ�̬�˶�ģʽ��Ǩ��ѧϰ��һ���Ƚ�����ʵ�ֵIJ������������ڱ����У��÷�����Ҫ���ع���ʱ�յ�����Ϣ����ģʽGRU����ѧϰ.
2.3 ���ڶԱ�ѧϰ�ĵ�GRUѵ��
ʹ�öԱ�ѧϰ����[26]�Ե�GRU����ѵ��.��ʱ������ xѵ���õ�һ�������� f��ʹ��H ( f (x ) , f(x+))? H ( f (x ) , f(x-))�����У�x+�Ǻ� x���Ƶ���������x-����x�����Ƶĸ�������H�Ƕ������������ڶ������������ƶ�.�Ա�ѧϰ����ʧ����LN�ɱ�ʾΪ
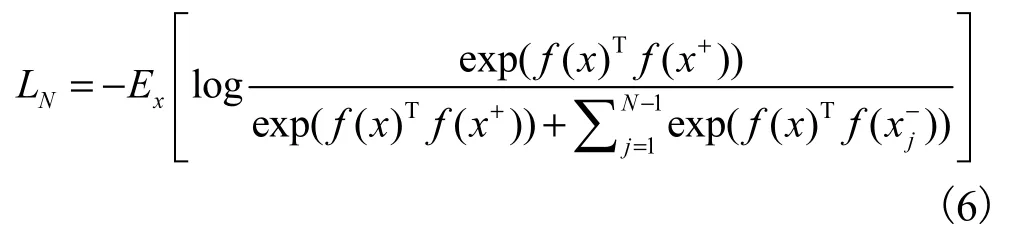
����EΪ����.ͨ����������������Ӧ�ã��������������ֶ�Խ��Խ�ã����ڱ��ģ���ʹ�����ɵ��������� GRU����ѵ�����Դﵽ���� GRU��ѵ������������ǿ���緺�����ܵ�Ŀ��.
��ͼ3��ʾ����֪�û�A���˶��켣���ù켣�����ɵ�������������ɫ��ǣ��������û������ߵ��ĵ�(С��Χ����)��
�����������ú�ɫ��ǣ��������û��������ߵ��ĵ�(Զ��������).����ͨ�������������ҵ�������ֶȵ��������������������Ͻ���ɸѡ��GRUѵ��ʹ��.

ͼ3 �Ա�ѧϰ����(�������ֶȸߵ���������)Fig.3 Contrast learning strategies (generatingpositive and negative samples with high discrimination)
���IJ��öԱ�ѧϰ���ԣ���ѵ�����������ݵ�ͬʱ��ҲҪ��֤���������Ŀ�����������ԣ������������������˷������ɵ����ݽ���ɸѡ.
2.4 �����������˷�
��Ǩ��ѧϰ�㷨�ͶԱ�ѧϰ�㷨���ɵ����������������ˣ���һ��ʹ�� MMD����[27]ȷ���������������ͳ������һ�£�
�ڶ���ʹ�ñ��������TrAdaBoost��EM ���㷨���������Ʒֺ���н�һ��ɸѡ�����ձ�֤ѵ������������չ����Ч��.
������MMD�������趨�����ֲ���s��r�ֱ�����û�ʱ��λ��Դ���ݼ�(source)���û�ʱ��λ���������ݼ�(resulting).��Դ���ݼ����������ݼ��������չ���ݼ���ͨ��������(��)�����ݵ�ӳ�䵽������ϣ�����ؿռ�(reproducing kernel Hilbert space��RKHS)����s��r֮���MMD�����ɶ���Ϊ

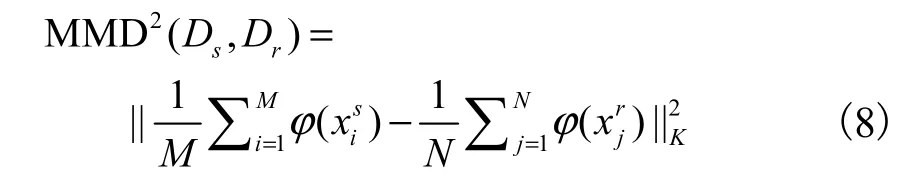
Ϊ��ɸѡ���ݣ����õ�����Ҫ������ݼ��������� MMD������ɵ�һ��ɸѡ�õ� MMDֵ��С���Ϸ���Ҫ��Ĵ��������ݼ�DFs.��һ��������TrAdaBoost��� EM ��˼�룬��Դ���ݼ����������ݼ������������б�ɸѡ���㷨�������£�
���룺����������������ݼ�DFs�����ñ�ǩΪ0��
�������ݼ���ѵ����Dt�����ñ�ǩΪ 1��
��������������Ϊ N.Ȼ����г�ʼ����������ʼ����Ȩ������Dw=(Dw1,�� ,Dwn+m)��
DFs�����ۼ�������ΪDws=(Dws1,�� ,Dwsn)��Dt�����ۼ�������Ϊ Dwt=(Dwt1,�� ,Dwtm).
For loop��1������N(ѭ������ 1��8)��
1.�� D = ( DFs�� Dt)������ D�������Ϊ n��m�����ϣ���Ϊ D1, �� ,Dn+m.
2.�������ϵ����Ӽ���Ϊ n��m ��.�趨ÿ�����ϵ�Ȩ��Ϊ

ʽ�У�ptΪ��t�����ϵ�Ȩ�أ�Ϊt�����е�i��Ԫ�ص�Ȩ��.
3.D���ϵ�ͳ�Ʋ���E��M�Լ���ǩ�����������ݣ�����EM����.
4.E-step��

ʽ�У�xi��ʾ�� i��������
zi��ʾ���Ӧ����������(xi, zi)��Ϊ��ȫ���ݣ�
��jΪģ�Ͳ�����
p(��)��ʾ����.
5.M-step��

ʽ�У�L(��)Ϊ��Ȼ����.
6.�õ� EM ��ģ�Ͳ��� �Ⱥ� D�ڵ� n��m�����Ͻ����б𣬲����������
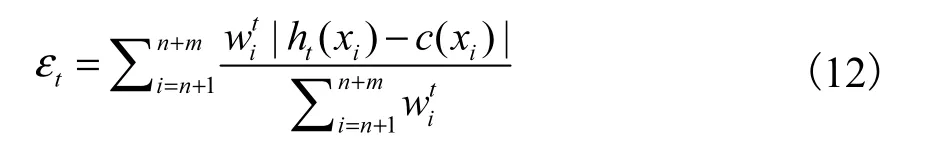
ʽ�У���t��ʾ�����ʣ�ht( xi)��ʾ������Ԥ�����(ֵΪ 0�� 1)��c(xi)��ʾ������ʵ�����.
7.��

������Ȩ��w
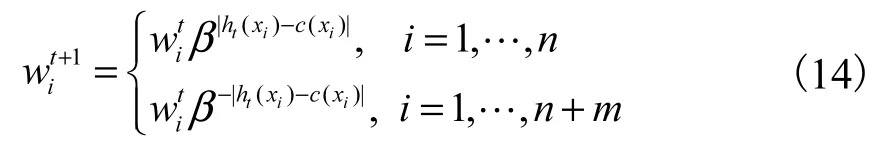

ʽ�У�DsΪ�˵����ݵ����ݼ���
DtΪʣ�����ݵ����ݼ���
ws��wt�ֱ�ΪDs��Dt����Ȩ��.
�����ݼ�Dt�е����ݽ������������õ�����Dtrans.
�����Dtrans= { x1, �� ,xk}���� xi��Dt��
Dtrans������Ӧ��Ȩ��Ϊ Wtrans= { wtrans.1, �� ,wtrans.k}��wtrans.i�� { Ds��Dt}��?wi�� m in(Wtrans).
���������������˷��Ĵ������õ��ϸ��ѵ�����������ٸ���Դ���ݼ��ڵĹ켣��ʽ(�����û�ID��ʱ��˳��)���ü����е����ݻ�ԭ�ɸ����ռ�켣x��x ={�� ,xt-1, xt, xt+1,��} ��x��Ϊѵ��GRU�������������.�������˷�������е�Ȩ�������ж������Ƿ�ϸ���˽��ڹ��˷����ڲ���Ч������ΪGRU�������������.
2.5 ����
����[28]�ǻ��ר�������һ���֣����ݹ��ܲ����Ϊ������������Э��������.����ѡ��������������.�ھ�������ģ���У����û�����������ʱ��λ����Ϣ x��Ϊ���룬���� x={��,xt-1, xt, xt+1,��}�������������ݵIJ�ͬ��ʽ���������ľ��߽������ѡ���GRU��ģʽGRU�ļ�������Ϊ�������.
����ϵͳ������Ϊ�������У�����������������ʱ�䡢�ռ�λ�ã��û����ƶ�״̬(����ͣ�����ǻ�)���ܻᵼ���������������λ�����Ϸ����ظ�����˵������������ݵĸ������������ж�Ӧ�ý��ĸ�ר�ҵĽ����Ϊ���.
��������Ҫѵ����һ�����������ھ��ж��������ݵ���ʽ������ѡ����ʵ����������Ϊ���.��������ģ�齫�������ݽ��д�����������Ͻ�������ͬ�ĵ�ϲ�.���õ������ݴ��϶�(�Գ��� 1Ϊ�ο�)���ἤ��� GRU �������
���õ������ݴ��ϳ���������ģʽGRU�����.
3.1 ʵ�����ݼ��Լ�����Ԥ����
3.1.1 ���ݼ�
����ʹ���� 1�������ݼ��� 2���ⲿ���ݼ�.�����ݼ�����ѵ�������Ե� GRU�����Լ�����ģʽGRU���磬�ᴩ�����ṹ��ѵ���Լ����ԣ�
2���ⲿ���ݼ�������ѵ��ģʽ GRU���磬���Ҳ��ΪǨ��ѧϰģʽ�е��ⲿ���ݼ�.
(1)�����ݼ���Gowalla check-in dataset�������ݼ��ǹ������ݼ��������������Լ����ݸ�ʽ��ͼ4��ʾ.

ͼ4 �û�ǩ����Ϣʾ��Fig.4 Example of user check-in information
(2)�ⲿ���ݼ���Ǩ��ѧϰ���Բ����漰�����ݼ���Facebook V��Predicting Check Ins���ݼ���Yelp Dataset Check Ins���ݼ�.�������ⲿ���ݼ������ݸ�ʽ�������ݼ�����һ�£����ܹ��ṩ�û���ʱ�չ켣��Ϣ�������Ա�ʵ�����漰����ؼ��ľ��ȡ�γ�ȡ�ʱ��3����Ϣ.
3.1.2 ���ݼ��ָ�
�������ݼ��У���ÿ���û��ļ�¼��Ϣ���зָ20%ѵ������80%���Լ�.��ͨ��ʵ�����ݷָͬ����ʵ�齫 20%��Ϊѵ�����ݣ�80%��Ϊ�������ݣ�Ŀ���������ֳ�����������ķ����ܹ�����������������������ϵͳ������.ȥ�������ݼ���ǩ����¼���ٵ��û����ݣ��������ݼ���IDΪ196585���û�ֻ������ʱ�յ��¼.
3.2 �Ա�ʵ��
3.2.1 ����ָ��
������ʵ���п����ȷ�ʡ��ٻ��ʵ�ָ�겻ͬ���Ա��Ŀ��ƶ���Ȥ����Ƽ�Ч�����۽�Ϊֱ����Ч�ķ����Ǽ������Ŀռ���������Զ��ʵ����㷨��Ԥ��������ͳ�Ʒ����ǹؼ�����ʵ���е��ֶ�.��tʱ��Ԥ��t��1ʱ�̵���Ȥ��λ�ã���� ¼ �� �� �� Ԥ �� �� x�� =( p txt��+1, p tyt��+1)�� �� ʵ ��x = (p txt+1, p tyt+1)��ŷ�Ͼ���D����
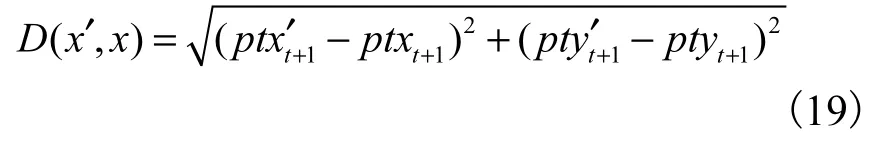
ʽ�У�x���ʾԤ������㣬x��ʾʵ������㣬ptxt��+1��ʾԤ�������ĺ����꣬ptyt��+1��ʾԤ�������������꣬ptxt+1��ʾʵ�������ĺ����꣬ptyt+1��ʾʵ��������������.
�ֱ����ϲ�ͬ�㷨������������մ�С����������У��õ��������� Q�������õ�Ԥ���������ֲ�����ͳ�������������ķ�λ��[29]�����ɵõ���ͬ�㷨��Ԥ�����ԱȽ��.�ķ�λ��Q1��Q2��Q3�ֱ�Ϊ Q ��������ֵ��С�������к��25%�����֡���50%�����֡���75%������.
3.2.2 ������ʵ������
���õĻ�����Ϊ�����ɷ�ģ�ͣ�DBSCAN������˹���ģ�ͣ�DBSCAN����.�����ɷ�ģ�ͺ�˹���ģ�Ͷ���Ҫ���DBSCAN��������Эͬ����.�䲽�����£����Ƚ��켣��ظ��ݲ�ͬ�û����ϳɸ����û���·�ߣ�
Ȼ��ֱ����������ɷ�ģ�ͺ�˹���ģ�Ͷ��û���·������Ԥ�⣻
�������DBSCAN������Ԥ�����������ϣ��õ��û��ۼ��϶��ʱ��λ�ã�������λ���Ƽ����û�.
3.3 �������
3.3.1 ���ڿ��ƶ�����Ȥ���Ƽ��Ա�
���ڿ��ƶ�����Ȥ���Ԥ����Ҫ��Ԥ��δ����1��ʱ�յ㲢����3�ֶԱȣ�ÿһ�ֶ��û����������ȡ 50%�IJ����������в��ԣ�ͳ�Ƴ������û�Ԥ�������ķ�λ�������ݴ˻����ķ�λ����ʽͼ.
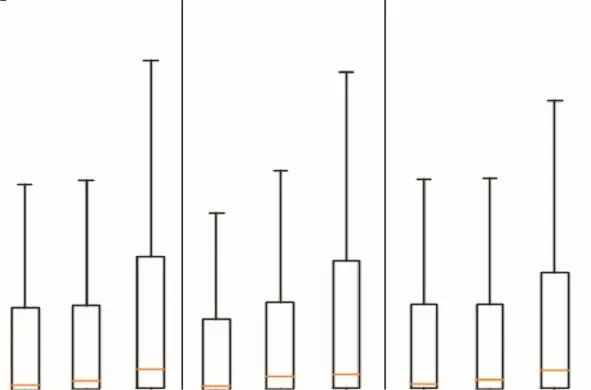
ͼ5չʾ�� 3�ֶԱ��㷨�Ķ��ڶԱ�ʵ����.�ɴ˶Ա�ʵ�����ɼ������ķ���(A)�������ɷ�ģ�ͣ�DBSCAN����(B)�ȸ�˹���ģ�ͣ�DBSCAN����(C)�����ܷ�����ָ���.��ͳ��Ԥ�����������λ�����棬���ĵķ����ȸ�˹���ģ�ͣ�DBSCAN��������λ��Ҫ�� 32%��65%���������ɷ�ģ�ͣ�DBSCAN��������λ��Ҫ�� 15%��47%��
�ɼ����ķ������ṩ��Ԥ�������и��õ��ȶ���.ͬʱ�ڼ���Ԥ��ʵ��ľ��������λ�����棬���Է��������ɷ�ģ�ͣ�DBSCAN���������ڸ�˹���ģ�ͣ�DBSCAN����.

ͼ5 ���ڿ��ƶ�����Ȥ���Ƽ��ԱȽ��Fig.5 Comparison results of short-term mobile points of interest recommendation
ͳ�ƽ�������ķ�λ���ܹ���ӳ���ƶ�����Ȥ��Ԥ�����ľ���.�ӱ�1�ɼ�����3�ֶԱ�ʵ���У����ķ���������������������ַ����������ŵ����ķ�λ��������ر����ڵ�3��ʵ���У���25%��Ԥ�����ľ��Ծ���С�� 0.53km(��ʽͼ���±߽�).���Ԥ�����������ķ�������ʵ������Ҳ�ܹ��Ϻõ�Ԥ����ƶ���Ȥ��Ķ���λ��.
�ڶԱ����ķ�λ����ͳ�ƽ�����棬��1�б��ķ���Ҳ�����˽Ϻõ����ܣ����и�С�����.���������ɷ�ģ�ͣ�DBSCAN�����ڵ�3�ֶԱ�ʵ���б��ֳ���Ϊ�����Ԥ��������ķ�λ�������ķ������������ַ�����Ԥ��������ķ�λ����25%��30%.
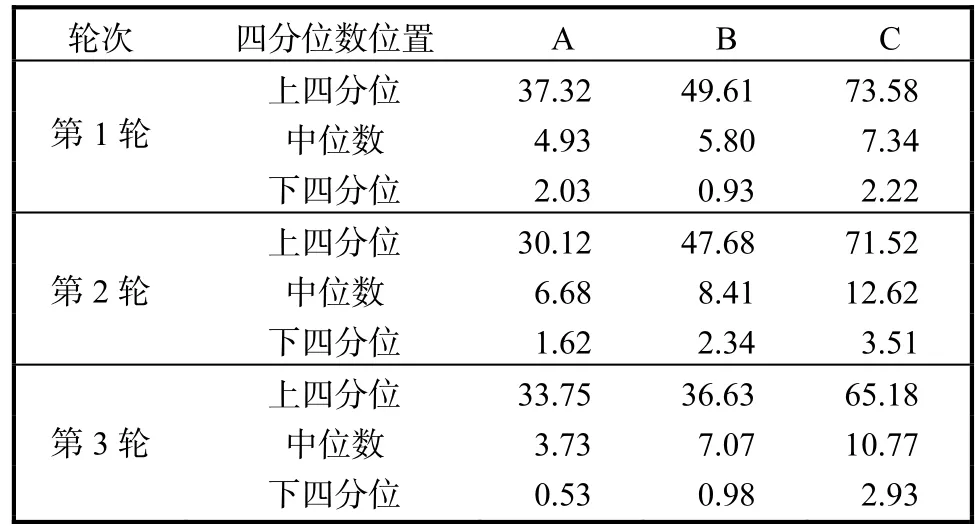
��1 ���ڿ��ƶ�����Ȥ���Ƽ����ͳ��Tab.1 Error statistics of short-term mobile pointsof interest recommendation km
�ڶ��ڿ��ƶ�����Ȥ���Ƽ��Ա�ʵ���У����ķ����������ŵ���λ�������ķ�λ������Ԥ���������չʾ���ȶ��Ժ�ȷ��.���ǣ������ķ�λ��������һ��ʵ����û��ȡ�����ƣ�����ԭ����������Ա�ѧϰ������չѵ������������ʹ����Ԥ��������.��������ԣ�����Ա�ѧϰ���Ժ�Ǩ��ѧϰ�����ܹ��ܺõؽ���Ԥ������ǿԤ��Ч�����ȶ���.
3.3.2 ���ڿ��ƶ�����Ȥ���Ƽ��Ա�
���ڿ��ƶ�����Ȥ���Ԥ����Ҫ��Ԥ��δ���ĵ�3��ʱ�յ㣬����ڿ��ƶ�����Ȥ���Ԥ��Ա�ʵ�����ƣ����� 3�ֶԱȣ�������ͬ����ͳ�ƱȶԷ�ʽ��������.ͼ6չʾ�� 3���㷨�����ڶԱ�ʵ����.�Ӵ˶Ա�ʵ�����ɼ�����˹���ģ�ͣ�DBSCAN����������֤Ԥ���ȷ�Ժ��ȶ��ԣ���ԭ�����ڸ�˹���ģ�͵����ڻ��Ʋ��������ɷ�ģ�ͺ� GRU������нϺõĶ��ڡ����ڵļ����Ԥ������.��ͳ��Ԥ�����������λ�����棬���ķ����������������ֶԱ��㷨������ 35%��65%����3��ʵ���о�δ����10km.
ͼ6 ���ڿ��ƶ�����Ȥ���Ƽ��ԱȽ��Fig.6 Comparison results of mid-term mobile pointsof interest recommendations
��2���г�����ϸ�����ڿ��ƶ�����Ȥ���Ƽ��Ա�ͳ�ƽ��.�����ɷ�ģ�ͣ�DBSCAN�������нϺõı��֣���ѧϰ�����ͼ�����������֤��Ԥ������ȷ��.���ǣ����ڸ÷���ȱ���˶Ա�ѧϰ���Ժ�Ǩ��ѧϰ���Եĸ�������Ԥ������з����������㣬Ԥ��������λ���ϸߣ����ڵ� 1��ʵ���������ֵ��Ϊ 13.36km.�����ķ����ڶԱ�ʵ���б��ֳ����õķ���������������Ϊ���������ݼ��е�ʱ��ģʽ��Ϣ������Ǩ�ƣ����Ա��ֳ����õ�Ԥ��ȷ��.

��2 ���ڿ��ƶ�����Ȥ���Ƽ����ͳ��Tab.2 Error statistics of mid-term mobile points of interest recommendation km
�Ա�ʵ��Ľ���������ڽ�����ƶ�����Ȥ���Ƽ�������ʱ����������ķ����ܹ�ͬʱ���ӶԱ�ѧϰ���Ժ�Ǩ��ѧϰ���Ե����ƣ����������˺��ܱ�֤Ԥ�����ķֲ����ȶ��ҽ���Ԥ�����㷨�������������ɷ�ģ�ͣ�DBSCAN�����Լ���˹���ģ�ͣ�DBSCAN����.
���Ĵӿ��ƶ���Ȥ����Ƽ���Ԥ���������֣������һ�ָ���������ṹ.Ϊ�����ѵ�������Ч������ǿ����Ԥ������ʱ�ķ���������������������Ǩ��ѧϰ���ԺͶԱȲ��Խ������ںϣ���ʹ��MMD�����ͱ��������TrAdaBoost��EM�㷨�������������й��ˣ���֤����������Ч�ԡ������ԡ��ֲ�һ���ԣ�����ʹ�ø���������ṹ�ܹ��ܺõؼ����ڲ�ר�Ҿ��߽ṹ�����Ƽ�.
��������ĸ����������ѧϰ���Լܹ��Ƚ����ں������㷨�Ľ��о��У����Կ��DZ任ѧϰ���Ի���������ѧϰ���ԡ���չר������ṹ��.
����ϲ�� ѧϰ����ʱ�չ켣 ���������еĹ켣���̵ij�������ѧ��������(���а�.�߿���ѧ)(2022��4��)2022-05-25��Խʱ�յ������Ĵ����Ľ���(2022��8��)2022-04-28��������ѧϰ���Եĸ���д����ѧ̽�������ɹ�֮·(�߿����)(2021��11��)2021-12-21Ӧ���ͱ��Ʋ�δ�ѧ����������ѧϰ���Լ�ʵ������ʦרѧ������Ȼ��ѧ�棩(2021��1��)2021-07-21̽������Ӣ��ʻ�ѧϰ��״��ʻ�ѧϰ�������ɹŽ���(2021��22��)2021-03-08���е�ʱ�մ���Сѧ��ѧϰָ��(���꼶)(2020��11��)2020-12-14�켣���ѡ�������ѧ(���Ű�)(2020��4��)2020-08-24�켣���ѡ�������ѧ(���Ű�)(2020��3��)2020-07-24����Ӣ�︴ϰ��ѧ�еĺ���ѧϰ���Ը������(2020��21��)2020-04-13��һ��ʱ�մ�Խ�����Ĵ��������꼶(2018��10��)2018-12-06